 |
v0.14.0 |
|
v0.14.0 |
Set by step example how to implement mix finite element and do hp-adaptivity
Here we present general procedure applied to h-adaptivity of mix problem. MoFEM is generic finite element code capable of solving problems from magnetics, mechanics of fluids and solids, and as a result of this operates on necessary complex data structures able to carry abstract problems. If you master this example, applying the same approach, you will be able to implement in similar way other problems, for instance, Discontinuous Galerkin Method, or thermo-mechanical coupled problem.
In this tutorial, we show how to implement h-adaptivity for mix transport formulation for stationary transport/heat-conduction problem (The Poisson equation). We focus on h-adaptivity, however, this implementation allows running problem with the arbitrary order of approximation and extension to p-/hp-adativity is possible.
Code relevant to this tutorial could be found in Mix transport element module. Plane source code for main program is available under link h_adaptive_transport.cpp, whereas main class implementation of finite element and finite element operators is available here MixTransportElement.hpp.
MoFEM is built on three pillars, PETSc library which manages abstraction related to the algebraic system of equations and delivers interface to several solvers, mesh-oriented database (MoAB) which manages complexities related to mesh topology and delivers various format readers and Boost library which through multi-indices manages access to containers with MoFEM data structures.
MoFEM handles complexities related to finite element method, degrees of freedom, approximation spaces and base functions. It provides tools and structures for implementation classical and nonclassical finite element codes and can handle linear, nonlinear and time dependent problems.
Here we are considering a problem
\[ A_{ij} \sigma_j + u_{,i} = 0 \; \textrm{on} \; \Omega \\ \sigma_{i,i} = f \; \textrm{on} \; \Omega \]
where first equation is a physical (constitutive) equation and tensor \(A_{ij}\) express material properties, for example, if \(A_{ij}\) is a diagonal matrix with single constant on diagonal we have an isotropic material. The second equation is conservation equation, which expresses law that mass or energy can ot be created or destroyed (close system).
Multiplying the constitutive equation by a test field \(\tau\) and integrating by parts over \(\Omega\) (taking into account the inhomogeneous Dirichlet boundary condition), we obtain
\[ \int_\Omega A_{ij}\sigma_j \tau_i \textrm{d}x - \int_\Omega u \tau_{i,i} \textrm{d}x = \int_{\Gamma_\textrm{u}} \overline{u} \tau_{i} n_i \textrm{d}\Gamma ,\quad \forall \boldsymbol\tau \in H(\textrm{div},\Omega) \]
while from the equilibrium equation by multiplying by test field \(v\) we obtain
\[ \int_\Omega \sigma_{i,i}v \textrm{d}x = \int_\Omega f v \textrm{d}x, \quad \forall v \in L^2(\Omega). \]
Before we look into implementation details, you can run simple example
where
Above code produces output files, out_0.h5m, out_1.h5m, ... where number of files is dependent on number of refinement levels. You can convert those files to VTK format running script
and post-process results in ParaView http://www.paraview.org.
As result of post-processing in ParaView we have created following output

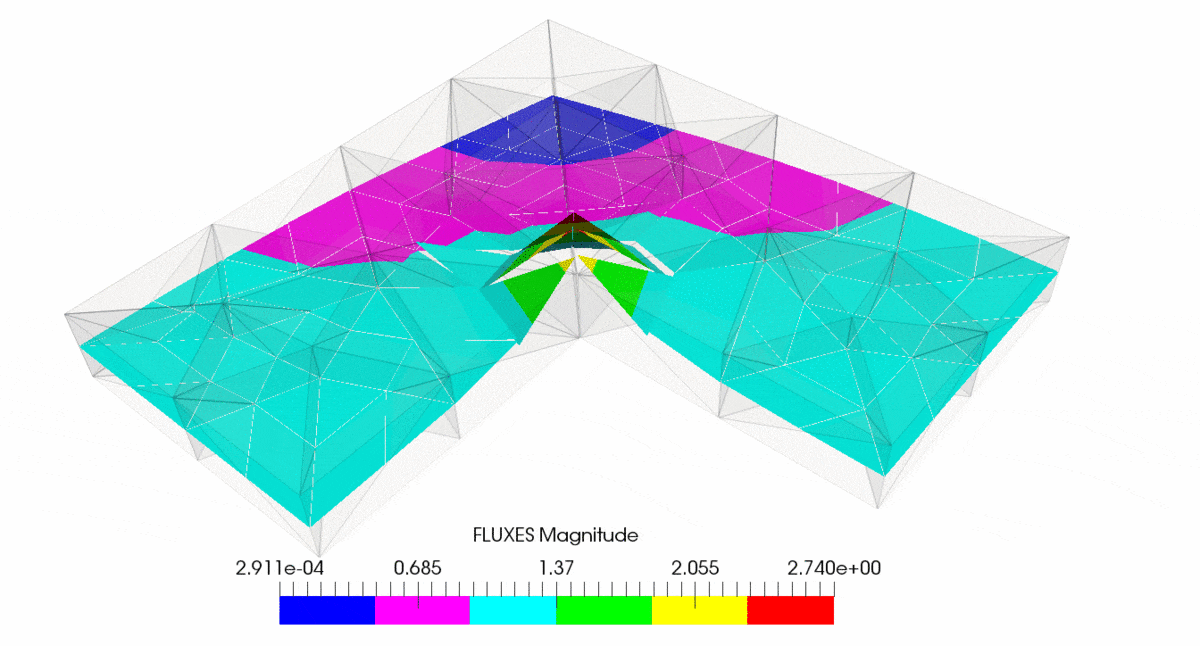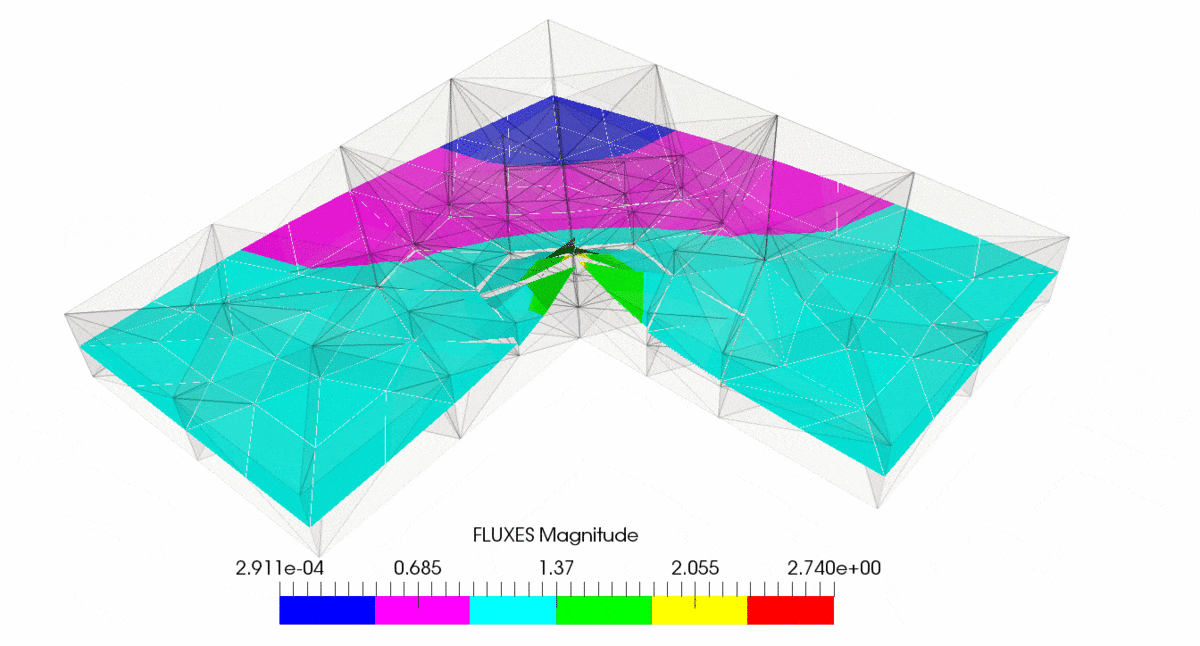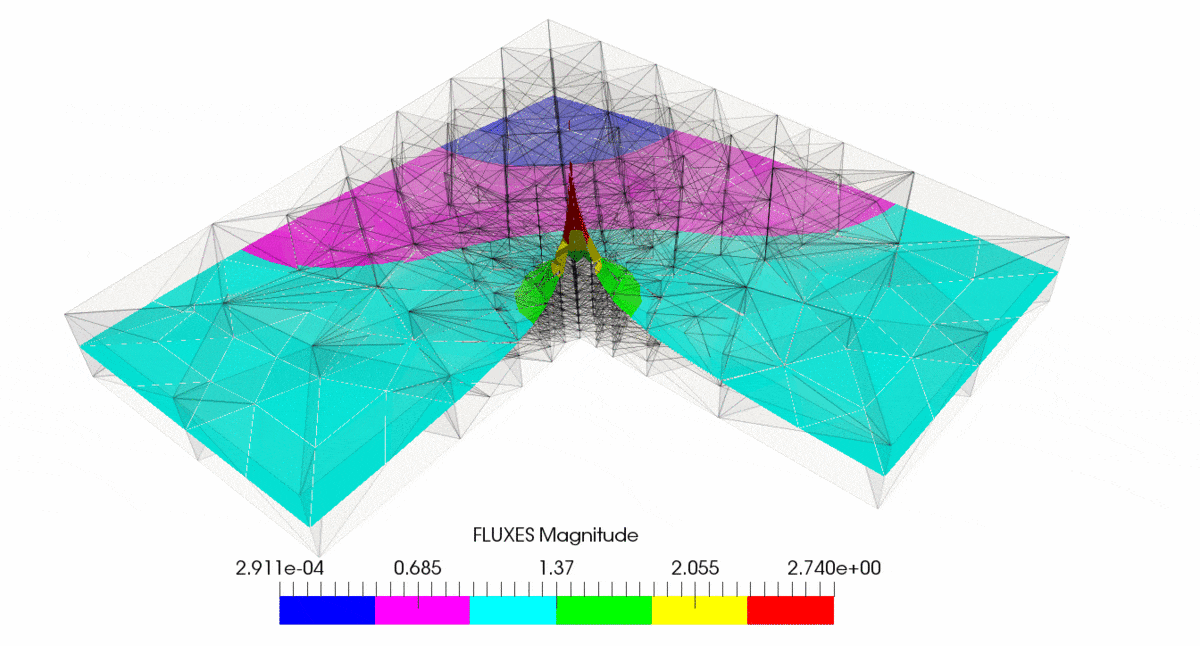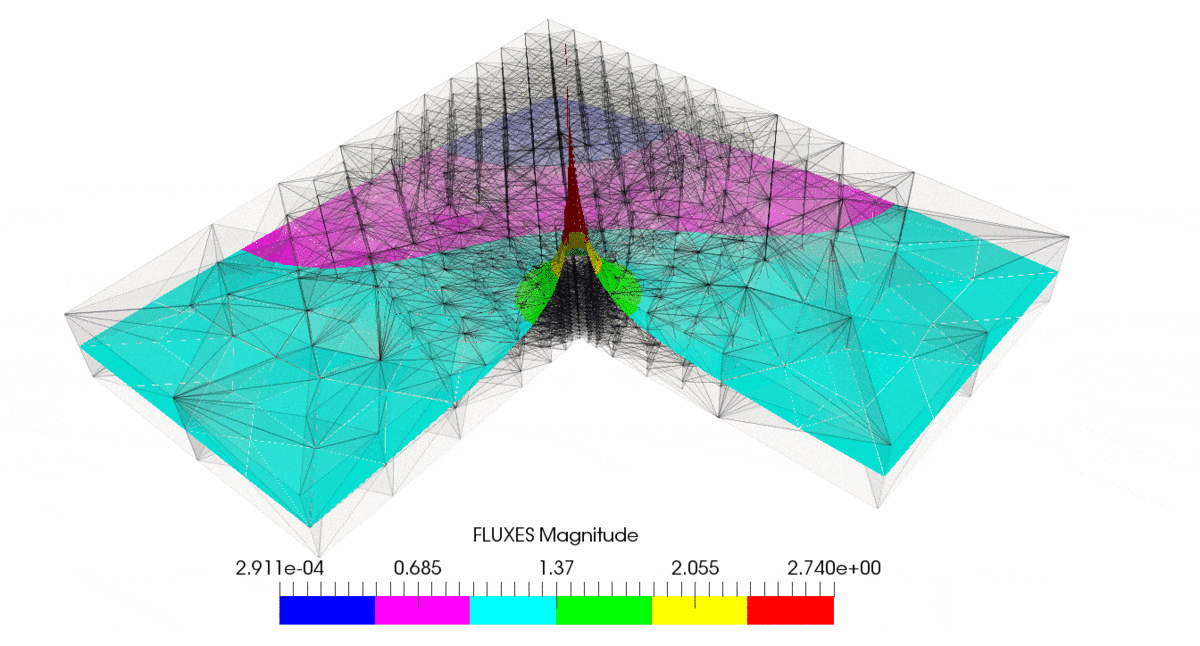
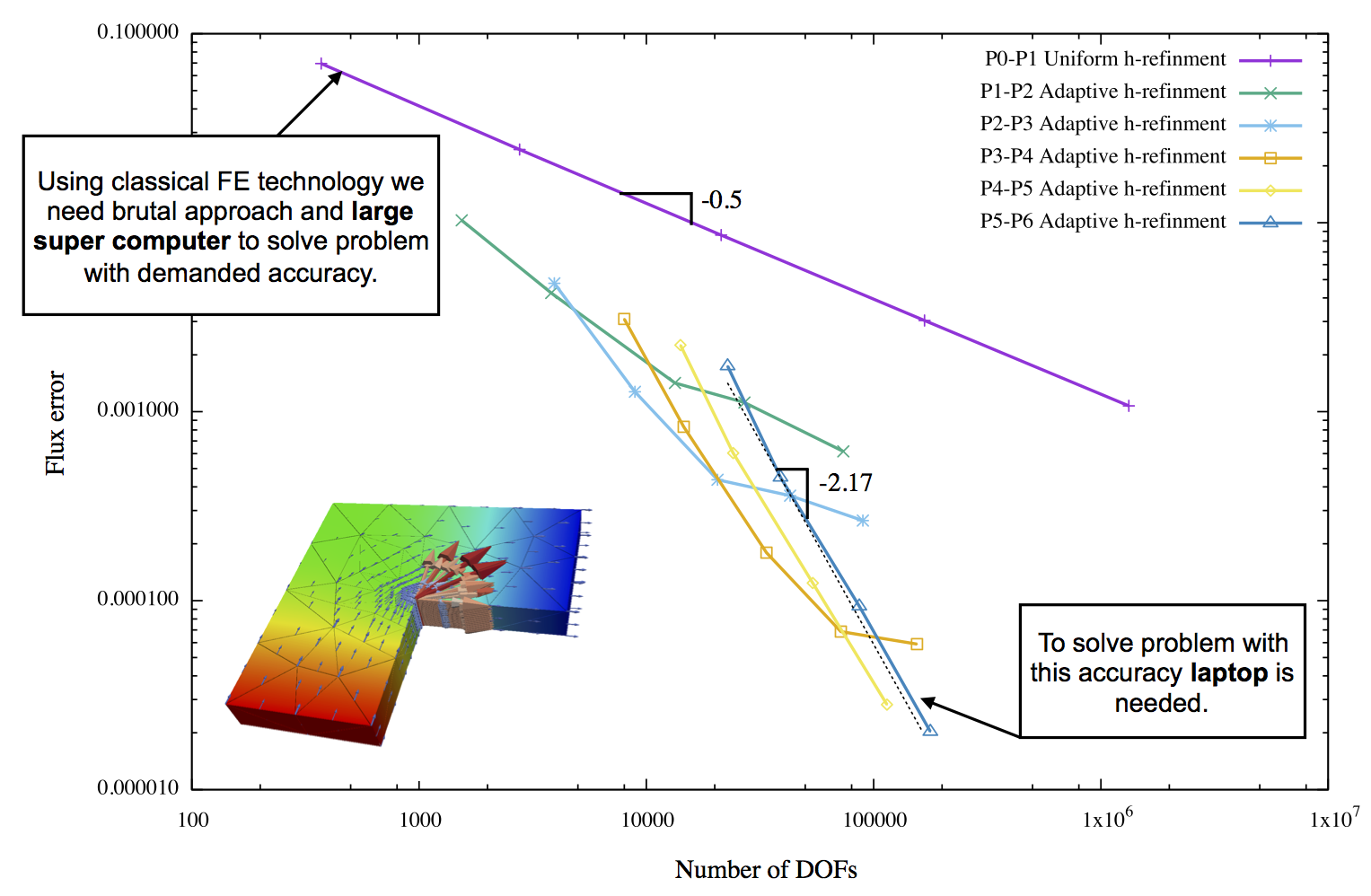
You can note that subsequent mesh refinement reduces error and make it more uniformly distributed through the mesh. You can also observe that mesh is getting denser at the corner where singularity is located.
MoFEM::BitRefLevel is a generic tool which allows working on several overlapping meshes, partially sharing entities and topology. In the context of this problem, we would use it to create and work with a hierarchy of mesh refinement.
For each entity in a database (vertex, edge, triangle, quad, ..., tetrahedra, brick, prism, ...) we attach bit tag, i.e. MoFEM::BitRefLevel. Using that tag we can make selections of entities and other operations on meshes.
It will be easier to understand if you look at the figure below
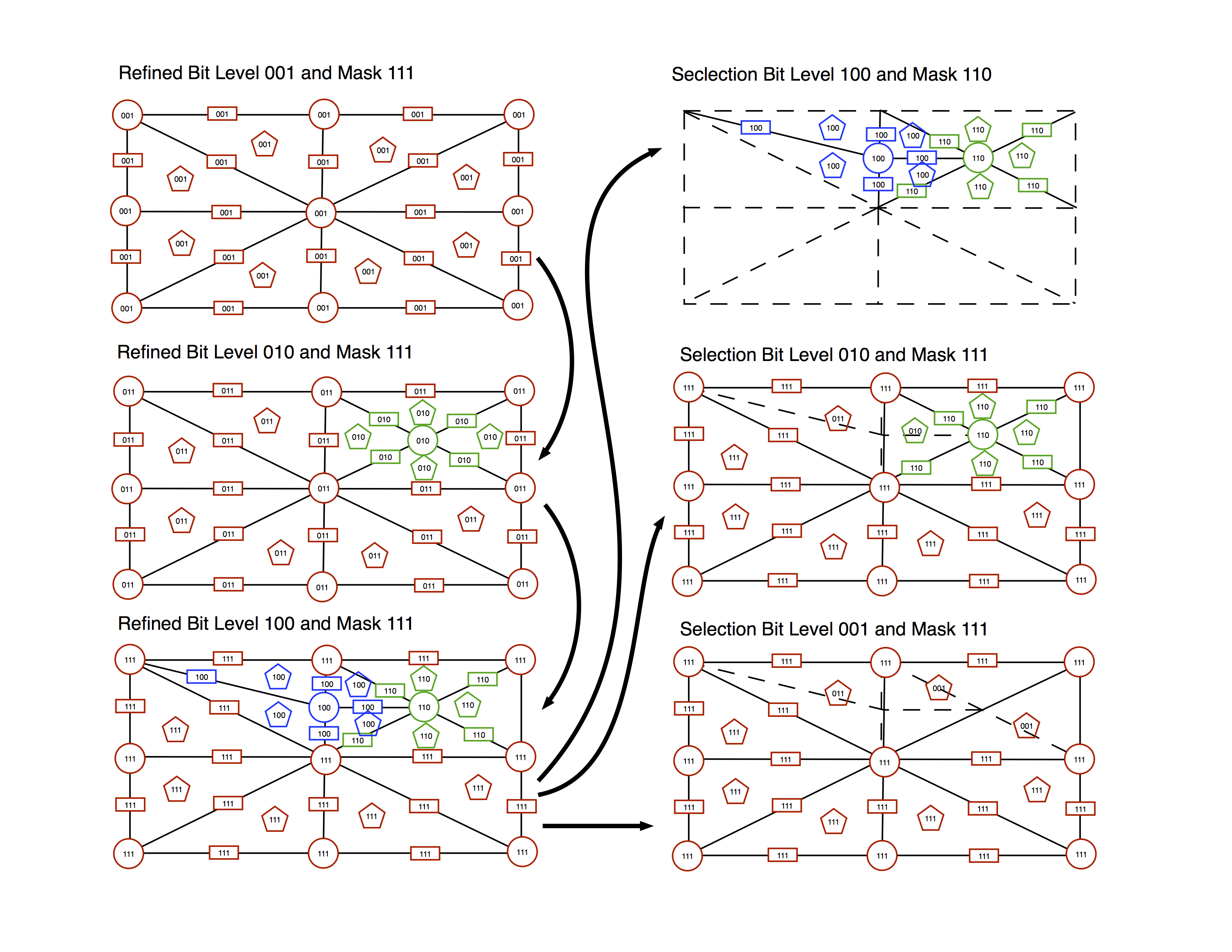
Imagine that we load the mesh with the topology like in the top-left figure. We seed the mesh (MoFEM::Interface::seed_ref_level) by tagging each entity with the first bit on, i.e. 001.
Next, we refine by splitting one of the edges, see middle-left figure. You can understand that as edge-splitting-mesh refinement, see [63]. As the result of this mesh refinement, new vertex in the middle of the edge is created, four new edges and four triangles. The remaining of mesh entities is part of old and new mesh level. As a consequence, entities which are shared between the second mesh and first mesh have two bites on, i.e. 011, since those are coexisting on two meshes. New entities have the only second bit on, i.e. 010.
In the next step, we made third mesh refinement. The procedure repeats, we have some new entities which have the only third bit on, i.e. 100, some entities are shared between refinement second and third, those have third and a second bit on, i.e. 110, and some entities are shared between all refinement levels, i.e. 111. In current implementation, we assume that user would not have more than 32 refinement levels. However bit squashing and bit level deletion allows form deep (more than 32) mesh refinements.
Physically all three meshes overlap, we do not delete overlapped entities or create new whole mesh each time. It is the reason behind that since we like to transfer data between different refinement levels without the redundancy and unnecessary copying and communication between processors if the mesh is distributed.
Now we present examples of mesh selections; you can practically do everything that you do with bits, see https://en.wikipedia.org/wiki/Bitwise_operation#Bit_shifts. For example;
That allows to project data between meshes, do calculations on the part of the mesh, to introduce cracks, make topological changes like face flipping. Note that problem below is defined for particular bit levels. See link Get entities and adjacencies for details how to get entities and adjacent by bit refinement levels.
We consider the problem which potentially can have complex geometry and a non-trivial set of boundary conditions. Here we use Gmsh (see http://gmsh.info) to generate the mesh. In this section, we focus attention on how to read mesh file and how to apply some arbitrary boundary conditions on that mesh.
The first step is to create mesh database, where information about the problem is stored. We create MoAB (see http://ftp.mcs.anl.gov/pub/fathom/moab-docs/) instance and interface to it
Once we have created mesh database, we get from command line name of file which we like to load
where here we are using PETSc function to do that, see http://www.mcs.anl.gov/petsc/petsc-current/docs/manualpages/Sys/PetscOptionsGetString.html for more details. Having mesh file name, we can load mesh, created in Gmsh, to database
MoFEM can read various file format in this example we are using mesh from Gmsh, where example file geometry is stored in file l-shape.geo and mesh is in l-shape.msh. For more details about file formats please look into MoAB documentation.
Creating MoFEM database to store information about fields, finite elements and problem, we link it to MOAB database and create interface to manage data
In file \erf l-shape.msh following geometry and mesh is described
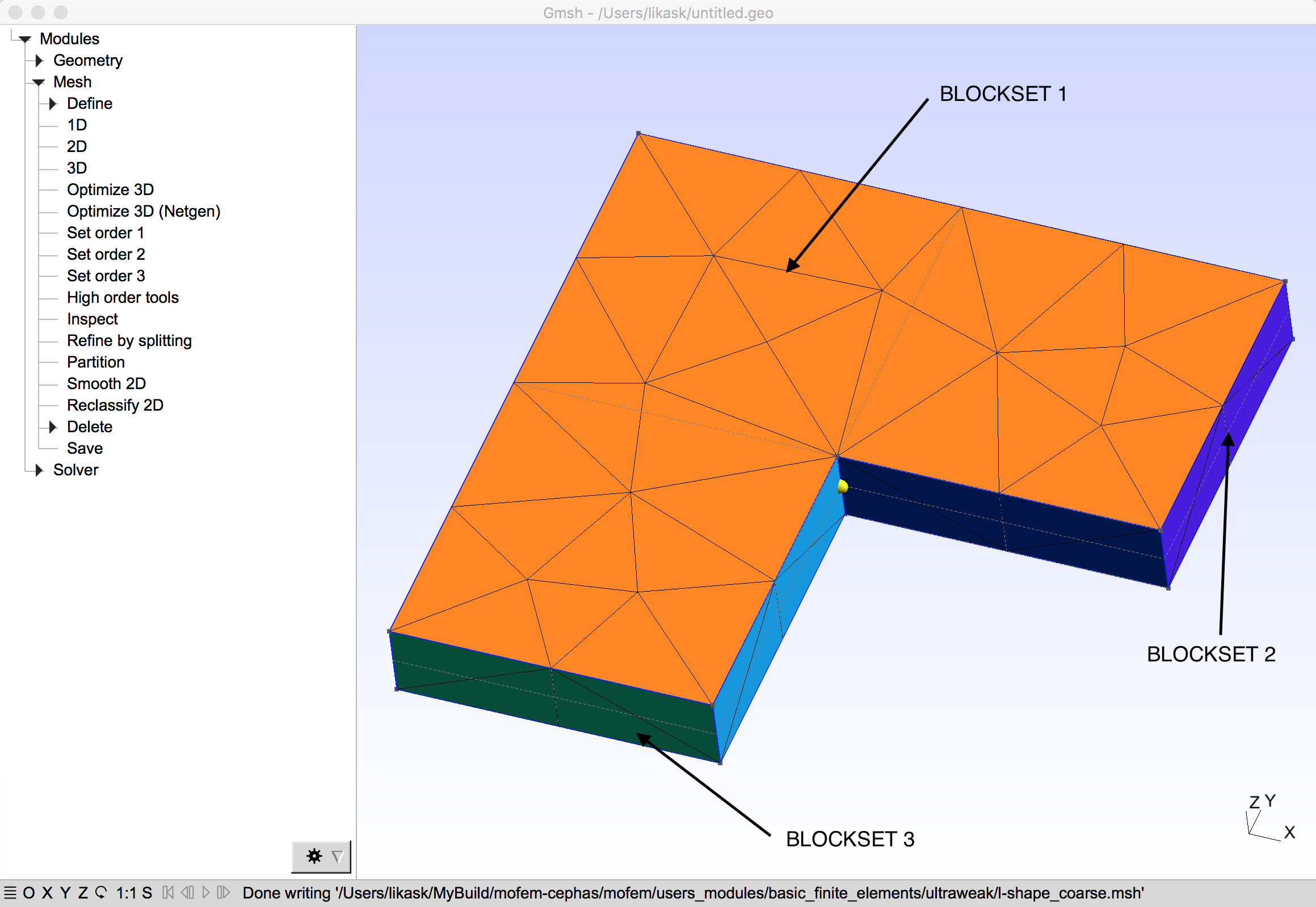
where as result of reading of that mesh into MoFEM database, following information is printed on the screen
read cubit meshset 12682136550675316737 type BLOCKSET msId 2 read cubit meshset 12682136550675316738 type BLOCKSET msId 3 read cubit meshset 12682136550675316741 type BLOCKSET msId 1
The output to the screen indicates that three BLOCKSETs are available. Those BOLCKSETs are interpreted as Physical Volume and Physical Surfaces which were created in Gmsh. User can create more sophisticated geometry or use more complex set of boundary conditions. Interpretation of BLOCKSETs is a matter of separate config file, which describes problem specific types of boundary conditions.
The interpretation of BLOCKSETs is done by the meshset config file bc.cfg,
According to that file, BLOCKSET 3 is set to be NODESET 1001 where temperature is applied \(u=0\, x \in \partial \Omega_u\) and BLOCKSET 2 is set to be SIDESET 1002 where flux is applied \(n_i\sigma_i = 1\, x \in \partial \Omega_\sigma\). On BLOCKSET 1 is the domain \(\Omega\) where problem is defined.
In the above example, temperature type, heat flux type and temperature volume are used. This is a matter of interpretation as well, we are using this convention to be consistent with other meshing programs like CUBIT where boundary conditions like that can be set directly. However, MoFEM user can set own types and attach own interpretation if needed.
Boundary condition meshsets are managed in MoFEM by MoFEM::MeshsetsManager interface. Using that interface user can access information about boundary conditions and add a new one. All modules and software components using that interface can easily share information through it. To get access to interface, user needs to query MoFEM for it, as follows
using interface we can read file bc.cfg, parse it and add boundary conditions. All this is automatized for user convenience and done with single interface method
In general, user can query about range of interfaces giving access to specific tools. In this example we are using two types of interfaces, one to manage BLOCKSETs, i.e. MoFEM::MeshsetsManager and another for refining meshes, i.e. MoFEM::MeshRefinement.
We start with calculating initial problem on mesh created with Gmsh. The problem is broken down into several stages, implementation of a mix transport problem is in ExampleMix which is derived from MixTransport::MixTransportElement.
In class MixTransport::MixTransportElement all operators for evaluating matrices, the right-hand side vector, error evaluation are implemented. Moreover methods for declaring and defining fields, finite elements and problems are added. This class could be used by other users, solving similar problems.
In derived class ExampleMix, particular functions for given transport problem with h-adaptivity are implemented. The method handles specific boundary conditions for this example.
The general procedure to solve problem looks like follows
such procedure will look very similar to other problems, where we set-up problem, apply boundary conditions, solve problem and postprocess results.
Some MoFEM functions and philosophy of building problem are explained in minimal_surface_equation, please look into that document for further explanation.
In MixTransport::MixTransportElement::addFields, we declare and define fields and add entities to those on which given field is spanning.
Note that in the first two lines we declare two fields FLUXES and VALUES. We define fields, by setting space to HDIV and L2, respectively. The fourth argument in functions MoFEM::Interface::add_field sets number of coefficients. Since we have vector and scalar field, number of coefficients is 1. If for example we would like to have second rank field for HDIV space and vector field for L2 space, number of coefficients would be three. Note that in general case you can set the field on part of the mesh and on some part it could be 3d field, 2d or 1d.
Function MoFEM::Interface::add_ents_to_field_by_TETs adds entities to a field, in this case, we like to solve the problem on whole mesh, so all entities from root meshset are added. Since we span that field on tetrahedra and all lower entities field is in 3d. The dimension of field is dictated by a dimension of entities.
In the following part of the code we declare finite elements, implementation of elements is done separately. By definition of finite elements, we are simply telling code on what fields given finite element operates. Domain of elements, i.e. entities on which elements integrate operators could be declared on the part of the mesh where the field is given. If you declare element on entities on which fields is no spanning, that element will have zero number of degrees of freedom.
In this example, we have four kinds of finite elements MIX, MIX_SKELETON, MIX_BCVALUE and MIX_BCFLUX.
Function MoFEM::Interface::add_finite_element adds the element of given name to the database, the second argument indicates that if the element of such name already exists do not throw the error. When the second argument is not given default behaviour is that error is thrown if the element already exists.
Function MoFEM::Interface::modify_finite_element_add_field_row, MoFEM::Interface::modify_finite_element_add_field_col and MoFEM::Interface::modify_finite_element_add_field_data define on what fields given element operates. You can think that this corresponds how you define the bilinear form for your operator, what is the first and second argument. Also, you specify data, for example, permeability could be given as a separate field which needs to be evaluated at integration points to assemble matrix. In that case you add that information using MoFEM::Interface::modify_finite_element_add_field_data.
Function MoFEM::Interface::add_ents_to_finite_element_by_type adds tetrahedral and triangles to given element respectively. You can think about tetrahedral and triangles as domains on which you perform the integration. Note that field can be spanned on tetrahedral (3d entities) but you can integrate on triangles, then on such element trace of field on the triangle is available from that element.
Note part of the code
which iterates over all BLOCKSETs on which MAT_THERMALSET is defined, then it gets information about material parameters and range of tetrahedral entities in that block. Next, it adds those tetrahedral to MIX finite element. In addition, it takes all adjacent triangles to tetrahedra and adds those entities to MIX_SKELETON finite element.
Adding elements to MIX_BCVALUE and MIX_BCFLUX is implemented in the next section. In above code, those finite elements are only declared and defined, but not yet implemented. Declaration, definition and implementation are independent of each other. You can use two different implementations of the same element.
In ExampleMix::addBoundaryElements, loop over boundary BLOCKSETs is made to get triangles in that BLOCKSET. Then appropriate triangles are added to MIX_BCVALUE and MIX_BCFLUX
Note that, at the end of the above code, the skin from full mesh is taken, i.e. triangle elements on boundary of meshet. Then, triangles on the boundary (skin) on which values or fluxes are not set are used to set zero-flux boundary condition.
In addition, function
and
are implemented. Those functions are used to evaluate values and boundary conditions at integration points. For more details how those functions are used look into MixTransport::MixTransportElement::OpRhsBcOnValues and MixTransport::MixTransportElement::OpEvaluateBcOnFluxes, those classes are implementations of operations on particular elements which are later explained.
Once fields and finite elements are declared and defined, we build/rebuild data structures carrying information needed to do the analysis. Note that function below is general, takes into account that problem could be built on several refinement levels, and if only the necessary part of structures if rebuild in subsequent mesh refinements.
The mesh MoFEM::BitRefLevel and related details with mesh refinement are described in the following sections. Here we focus only on declaring, building and partitioning problem for parallelized calculations.
MoFEM can work on partitioned meshes and parallel algebra and calculations. However, here we assume that mesh is the same on all processors, only calculations, matrices and vectors are distributed.
In the above code, several key functions are used. Function MoFEM::Interface::build_fields builds field data structure by construction degrees of freedom on each entity on which given field is spanning. For example, for L2 space, DOFs are only on tetrahedra which were added to the field. For H-div space is the more complex case, degrees of freedom are associated with triangles and tetrahedra, but a number of degrees of each type of entity depend on approximation order, for details look to [1].
At that point, field structure is created including DOFs on entities. Such structure can carry information about approximation order and values of a field. For example, you can do algebraic operations on field values directly mofem_field_algebra.
No indices are attached to DOFs since indices depend on a number of processors on which solution is carried on, partitioning method or directly type of problem which you like to solve.
Function MoFEM::Interface::build_finite_elements is used to build data structure. You can note that, in the above code, in subsequent mesh refinements, elements are added to the database, no whole base is rebuilt from scratch. At that point, information about degrees of freedom of fields acting on the element is aggregated. Finite element is problem independent.
Once fields and finite element structures are built, we can build problem. Domain of the problem, its size and structure of the matrix are uniquely defined by finite elements and fields on which element operates. First, a problem is declared using MoFEM::Interface::add_problem, where the argument of the function is the name of the problem which we like to add. Next we define problem, by setting finite elements, this is done using function MoFEM::Interface::modify_problem_add_finite_element where elements are added to the problem.
To build problem, we need to set MoFEM::BitRefLevel to the problem. In short MoFEM::BitRefLevel allows selecting a refined mesh on which we like to solve our problem. The details and unique flexibility of MoFEM::BitRefLevel are explained in Explaining mesh BitRefLevel.
Having all those stages done, at that point, structure of algebraic equations emerging from problem definition, finite elements, fields and domains on which finite elements and fields operate. That defines the structure of sparse matrix and structure of parallel vectors which ghost values.
At that point, we have defined and partitioned problem and that is enough to construct distributed matrices and vectors. The sparsity of the matrix, adjacencies and other bookkeeping operations are handled by MoFEM and PETSc.
Functions and use of below code have been explained earlier in minimal_surface_equation;
At this point, we have all data structures necessary to solve the problem. Now we focus attention on the implementation of finite element instances and solution procedure. In essence, we need to assemble matrices and vectors, enforce constraints, solve a linear system of equations and post-process results.
Definition of the finite element allows building the structure (adjacency) of the matrix, however, assemble (calculate) matrix we need finite element class implementation and its instance which will do the work. MoFEM allows implementing finite element at a low level, however, except special cases, a generic finite element class implementations can be used, where some operations like calculation of Jacobian, face areas and normals are implemented. Generic finite element classes enable us to focusses attention on the implementation of the bilinear form and its algebraic representation. That is numerical integration and evaluation of physical equations, evaluation of base functions and fields. The implementation of generic finite element is done by user data operators, see tutorials FUN-0: Hello world and COR-2: Solving the Poisson equation. Class of user data operator is inherited, and problem specific application is by function overloading. From user data operator class, we have access to base functions, integration points, local and global indices and values of DOFs. etc. UserDataOperator is run for entities on the element, on which approximation base is constructed.
In MixTransport::MixTransportElement class we create two generic finite element instances, i.e. MixTransport::MixTransportElement::MyVolumeFE and MixTransport::MixTransportElement::MyTriFE.
Those two finite element classes have method MoFEM::ForcesAndSourcesCore::getRule overloaded, which sets rank of integration rule on the element. The programmer needs to set integration rule, since he knows what will be integrated.
MoFEM bases on that function and higher order of approximation base functions sets precalculated in integration points and weights. In some classes, the programmer would like to use own integration rule, that could be easily done as well, but we postpone explanation how to do this to another example. If you like to see how it works in practice, please have a look here Post Process.
Now we can add tasks (UsersOperators) to finite element, which will do a sequence of calculations. However, before we show how to implement UsersOperators, we show first how finite element objects are used.
In the previous step, we have constructed matrices and vectors, next step is to calculate matrices and vectors and to solve the linear system of equations. At that point, we not yet focus how to integrate local finite element matrices, showing only how a solution of this problem is constructed. Numeration of DOFs, looping over finite elements, parallelization of the problem or assembly itself is handled by MoFEM.
The function
can be divided into several stages. First, we will focus on the calculation of essential boundary conditions. We already defined boundary where flux is applied, however unlike in standard FE formulation where nodal shape functions are used, for H-div space we need to apriori calculate values of degrees of freedom for essential boundary conditions. Exploiting properties of H-div space, trace of base functions on the boundary can be evaluated element by element, where for each boundary triangle small system of linear equations is solved.
Note that first line in the code above cleans vector of operators on the element instance (element object could be used before doing other tasks), second line adds operator MixTransport::MixTransportElement::OpEvaluateBcOnFluxes to the finite element instance. The operator has an argument vector D0 in which DOF values for essential boundary conditions are stored. The third line makes the loop over all elements in the problem (name of the problem is the first argument and the finite element is the second argument) and evaluates operators of element instance for object MixTransport::MixTransportElement::feTri. It is clear here that definition of element is separated from its implementation.
The similar procedure is repeated to calculate matrix and the right-hand side vector
where the calculation of matrix and right-hand side vector is broken down into several stages, where each sub-matrix is calculated by an user operator acting on finite element entities. Note that this time integration is over volume element, i.e. MixTransport::MixTransportElement::feVol. Finally, this part of code ends with the loop over all MIX finite elements in the MIX problem. If calculations are done in parallel, MoFEM manages related complexities transparently.
To complete calculations we have to integrate natural boundary conditions, i.e. enforce Dirichlet boundary condition
This procedure looks very similar to what has been done before, we clear existing operators on MixTransport::MixTransportElement::feTri, add operator MixTransport::MixTransportElement::OpRhsBcOnValues and loop over all surface elements where Dirichlet boundary is set.
At this point, we have created and assembled linear system of equations, we have not given an explanation how to do integration at user operator level, this will be explained later. At this point, we will show how to enforce essential boundary conditions. We have calculated values of DOFs already. Now we have to modify matrix and the right-hand side vector
while operator MixTransport::MixTransportElement::OpEvaluateBcOnFluxes is executed, it records indices of DOFs for which essential boundary conditions are applied. These DOFs are accessed by MixTransport::MixTransportElement::getDirichletBCIndices. We use those indices to zero rows of matrix Aij and insert 1 on diagonal. In addition, we fill the right-hand side vector with previously calculated vector D0. This operation is performed with PETSc function MatZeroRowsIS (http://www.mcs.anl.gov/petsc/petsc-current/docs/manualpages/Mat/MatZeroRowsIS.html)
At this point, we can solve system of equations
For details about the code above, we refer to PETSc user manual https://www.mcs.anl.gov/petsc/documentation/index.html.
The last operation at that stage is to store results on the mesh
You can think about MoFEM as a link between algebraic structures (e.g. vector) and mesh. Function MoFEM::Interface::set_global_ghost_vector is an example of this, using it you can transfer field values from mesh to vector and reverse of it.
In MoFEM, we apply general procedure, recognising in the typical finite analysis, to calculate matrices and vectors we make loops. Loop over finite elements on given partition, loop over entities in the elements (e.g. triangle is composed of entities like vertices, edges and triangle itself) and build on those entities base functions. Finally loop over integration points, where base functions are evaluated and local element matrix assembled.
Performing those loops, MoFEM manages associated complexities, like extraction of global and local indices or DOFs values, evaluation of base functions and derivatives and other typical operations.
All this work is done by generic finite element, the basic finite element instance is built on MoFEM::FEMethod, then more advanced structure recognising that finite element entity is composed of lower dimension entities is MoFEM::ForcesAndSourcesCore. MoFEM::ForcesAndSourcesCore allows to add so-called user operators, which are classes operating on each lower dimension entities and performing loops over integration points.
From class MoFEM::ForcesAndSourcesCore, there are more specialised classes like MoFEM::VolumeElementForcesAndSourcesCore, MoFEM::FaceElementForcesAndSourcesCore and others, see Forces and sources . Those elements recognise the fact that for example working with a volume (3d) finite element you would like to calculate volume or use appropriate integration rule. From other hand, working with faces like triangles, MoFEM::FaceElementForcesAndSourcesCore, you would like to know what is the area of the face or its normal and tangent vectors. Derived classes like MoFEM::VolumeElementForcesAndSourcesCore delivers tools for finite element programmer to do the specific job.
In this example, we use functionality of MoFEM::VolumeElementForcesAndSourcesCore by creating new class MixTransport::MixTransportElement::MyVolumeFE that derives from the existing class. The derived class inherits the properties of the base class, and you can add or override methods and properties as required. Each class has method MoFEM::ForcesAndSourcesCore::getOpPtrVector, returning reference to vector of shared pointers to MoFEM::ForcesAndSourcesCore::UserDataOperator, i.e.
Instances of operator classes derived from MoFEM::DataOperator. MoFEM::ForcesAndSourcesCore::UserDataOperator does particular jobs, for example, calculating field values at integration points, integrating mass or stiffness matrix. Finite element instance can run the sequence of user operator in the order you add them to share common data structure, here MixTransport::MixTransportElement itself. So for example, in one operator you can calculate gradients of displacement field at each integration point, in another, you can symmetrize gradient to calculate strain and in following to calculate stress and another to calculate the vector of internal forces. You break down the big job into smaller components, which you can use in several different contexts and easily test them one by one, making debugging easy. That is general philosophy of MoFEM, that complex and difficult problems are composition of small and simple tasks.
Class MoFEM::ForcesAndSourcesCore::UserDataOperator is inherited by MoFEM::VolumeElementForcesAndSourcesCore::UserDataOperator or MoFEM::FaceElementForcesAndSourcesCore::UserDataOperator and other user operator classes associated with vertices and edges. User operator class has two types of functions which need to be overloaded to do calculations, and they are
and
You have seen how we use those operators in the previous section. Here we show how to implement particular cases. The first doWork(int row_side, int col_side, ...) function is usually overloaded when you assemble matrix, the second is often used to assemble vectors. However, use of user operators is beyond assembly of matrices and vectors. Note that first doWork(int side, EntityType type, ...) function has an argument information about data in rows and columns, where second takes as an argument only rows or columns, depending on how user operator is set-up.
We will show how user operators work on two examples. First, we focus attention on term
\[ b_\mathbf{C}(\sigma,v) = \int_\Omega \textrm{div}[\boldsymbol\sigma] v \textrm{d}\Omega = \sum_\mathcal{T}^E \int_{\mathcal{T}^e} \textrm{div}[\boldsymbol\sigma] v \textrm{d}\mathcal{T} = \mathbf{q}_\textrm{h-div}^\textrm{T} \left( \sum_\mathcal{T}^E \sum_\mathcal{E_\textrm{row}}^e \sum_\mathcal{E_\textrm{col}}^e \sum_{g=0}^\textrm{N} w_g B^\textrm{h-div}_{i,i} B^\textrm{v} \right) \mathbf{q}_\textrm{v} = \left(\mathbf{q}_\textrm{h-div}\right)^\textrm{T} \mathbf{C} \mathbf{q}_\textrm{v} \]
were we implement matrix \(\mathbf{C}\)
\[ \mathbf{C} = \sum_\mathcal{T}^E \sum_\mathcal{E_\textrm{row}}^e \sum_\mathcal{E_\textrm{col}}^e \sum_{g=0}^\textrm{N} w_g B^\textrm{h-div}_{i,i} B^\textrm{v} \]
Note that in this case, where we have H-div space on rows and L2 space on columns, we have
\[ \mathcal{E}_\textrm{row}=\{ TRIANGLES\,\times\,4, TETRAHERAL \},\quad \mathcal{E}_\textrm{col} = \{ TETRAHEDRAL \} \]
You can notice three loops, over elements, entities on element and integration point. The first and second loop are managed by MoFEM while the last one over integration points where a particular operator is evaluated is implemented by programmer, as shown below
Note that we integrate over tetrahedra. Thus operator MoFEM::VolumeElementForcesAndSourcesCore::UserDataOperator is inherited. The class constructor MixTransport::MixTransportElement::OpVDivSigma_L2Hdiv::OpVDivSigma_L2Hdiv takes an argument PETSc matrix and set variable sYmm to false, since matrix \(\mathbf{C}\) is non-symmetric. Moreover, constructing operator we indicate that in the first argument of bilinear form we take field FLUXES and in the second argument of bilinear form we take field VALUES. Finally, in the constructor of operator we indicate that we like to loop over all possible combinations of entities on rows and columns, by setting OPROWCOL from enum type MoFEM::ForcesAndSourcesCore::UserDataOperator::OpType.
The real work is done in
MoFEM executes this method, in this particular case, for each combination of pairs
\[ \mathcal{E}_\textrm{row} \times \mathcal{E}_\textrm{col} = \{ \left(TRI_0, TET\right), \left(TRI_1, TET\right), \left(TRI_2, TET\right), \left(TRI_4, TET\right), \left(TET, TET\right) \} \]
Note that function MoFEM::DataOperator::doWork takes as argument row_side and col_side, which represent a local index of processed entity on rows and columns, respectively. Also, row_type and col_type shows the type of entity, for example, tetrahedra or triangle in this case. To see more details about a type of entities, local indices and canonical numeration see [69].
The row_data and col_data are data structures MoFEM::EntitiesFieldData::EntData carrying information about values of base functions, global and local DOF indices, DOF values on evaluated entities. For example, you can get indices on the row using row_data.getIndices(), or matrix of base functions at integration point as follows
In this case, each row of the matrix base_row_hdiv represents base function, where columns represent values of the element of base function vector. Look to MoFEM::EntitiesFieldData::EntData to see a range of data which is accessible by this data structure.
From inside MoFEM::VolumeElementForcesAndSourcesCore::UserDataOperator, we can access more finite element specific information, in that case volume element, for example,
and much more.
After above explanation, we focus on implementation itself, so finally we loop over integration points and calculate local matrix C, as follows
Here we are using Boost uBlas functions to do operations on local matrices. You can alternatively use tensor library implemented in MoFEM (FTensor) to do the job. Once local element matrix C is calculated, it is assembled into global matrix
where global indices on entities on rows and columns are easily retrieved by
where MatSetValues is a PETSc function documented here http://www.mcs.anl.gov/petsc/petsc-current/docs/manualpages/Mat/MatSetValues.html
To solve problem, other blocks of matrix need to be assembled, for details how is done please see MixTransport::MixTransportElement.
At this stage you could see how to assemble vector, we focus attention on the assembly of Dirichlet boundary condition. Note the Dirichlet boundary conditions in this formulation, are natural, i.e. enforced in a weak sense when a system of linear equations is solved.
This time, we will calculate integral
\[ \mathbf{f} = \int_{\Gamma_\textrm{u}} \overline{u} \tau_{i} n_i \textrm{d}\Gamma = \sum_\mathcal{T}^E \int_{\partial\mathcal{T}_\textrm{u}} \overline{u} \tau_{i} n_i \textrm{d}\partial\mathcal{T} = \sum_\mathcal{T}^E \sum_\mathcal{E}^e \sum_{g=0}^N w_g \overline{u} B^\textrm{h-div}_{i} n_i \]
to do that we use following user operator class
Note that above class is derived from MoFEM::FaceElementForcesAndSourcesCore::UserDataOperator, since we integrate over triangles where Dirichlet boundary conditions are set.
In this case, the constructor has two arguments, reference to MixTransport::MixTransportElement object itself, and the right-hand side vector. We use cTx reference to access function evaluating boundary conditions. Constructing derived class, we are indicating that use field FLUXES and loop only over entities on the row, by setting OPROW from enum type MoFEM::ForcesAndSourcesCore::UserDataOperator::OpType.
The real work is done in
Since we loop only over row entities, the function doWork, looks different that that one to integrate matrix, it is simpler. It passes argument about side which is local number of entity for which operator is executed, type of entity and finally data structure
MoFEM executes this method, in this particular case, for only one entity, i.e.
\[ \mathcal{E}=\{ TRI \} \]
This is a consequence that testing functions on rows are in H-div space. Note that if the testing function would be in H-curl space, so for triangle loop on entities will involve three edges and triangle itself, from a testing function in H1 space loop will involve vertices, edges and triangle itself.
The integration takes place in these lines of the code
where getNormal() get normal of the face and cTx.getBcOnValues(x,y,z,value) calculates value of boundary condition at coordinates of integration point.
Finally, local entity local vector is assembled,
where VecSetValues is PETSc function, see http://www.mcs.anl.gov/petsc/petsc-current/docs/manualpages/Vec/VecSetValues.html for details.
In this example to estimate posterior error we follow paper [15]. This error estimator works well for mesh-dependent norms, for which is reliable and efficient. However, it is not efficient in natural norm of \(H(\textrm{div},\Omega)\times L^2(\Omega)\) [17].
Following paper [15], we consider bounds of the error estimator in respect to the mesh-dependent norms
\[ \| \boldsymbol\tau \|_{0,h} := \left( \| \boldsymbol\tau \|_0^2 + h \sum_{e\in\Gamma_h} \| \boldsymbol\tau \mathbf{n} \|^2_{0,e} \right)^{1/2} \]
and
\[ |v|_{1,h} := \left( \sum_{T\in\mathcal{T}_h} |v|^2_{1,T} + h^{-1}\sum_{e\in\Gamma_h} | J(v) |_{0,e}^2 \right)^{1/2} \]
where \(J(v)\) is a jump on the face \(e\) and h is is consistently replaced by the diameters of the actual elements and the lengths of the edges. \(\|\cdot\|_0\) and \(\|\cdot\|_1\) are Sobolev norms and semi-norm, respectively.
Our a posteriori estimator will be based on residuals. There will be contributions from the tetrahedra as
\[ \begin{split} \eta_{T,R,1} &:= \| \mathbf{A} \boldsymbol\sigma + \textrm{grad}[\mathbf{u}] \|_{0,T} \\ \eta_{T,R,2} &:= h\| \textrm{div}[\boldsymbol\sigma] -\mathbf{f} \|_{0,T} \end{split} \]
and from the jumps on the inter-element boundaries
\[ \eta_{e,R} := h^{-1/2} \| J(u) \|_{0,e} \]
The local error estimator is a weighted combination
\[ \eta_{T,R} := \left( \eta^2_{T,R,1} + \eta^2_{T,R,2} + \sum_{e \in \partial T} \eta_{e,R}^2 \right)^{1/2} \]
For convenience, we will also refer to the global sum
\[ \eta_{T,R} := \left( \sum_{T \in \mathcal{T}_h} \left[ \eta^2_{T,R,1} + \eta^2_{T,R,2} \right] + \sum_{e \in \partial T} \eta_{e,R}^2 \right)^{1/2} \]
This error estimator is reliable and efficient, and the upper bound is
\[ \|\boldsymbol\sigma^*-\boldsymbol\sigma\|_{0,h} + | u^* - u |_{1,h} \leq \frac{c}{1-\beta} \eta_R \]
where \(c\) depends on the shape parameter of \(\mathcal{T}_h\) and \(\beta\) is saturation parameter, see [15] for details. Lower bound is
\[ \eta_{T,R} \leq \| \boldsymbol\sigma^* - \boldsymbol\sigma \|_{0,h} + | u^* - u |_{1,h} + h \| f - \textrm{div}[\boldsymbol\sigma] \|_0 \]
Once we have residual error estimator we could do h-adaptivity, it is done by executing following code
where nb_levels is the number of refinement levels.
We focus attention on mesh refinement procedures in next section, but first we will show how to calculate residual error estimator using user operators. Function evaluating error is implemented as follows
Once the problem is solved, first we need to calculate jump on the skeleton. We simply doing this by applying the same procedure like before, adding appropriate entity operator to the element object and looping over all triangular elements in the problem, as follows
Note that entity operator MixTransport::MixTransportElement::OpSkeleton is executed for every element MIX_SKELETON. How this entity operator is implemented is described in the following section.
Once the jump is calculated, we can evaluate error estimator, by running sequence of entity operators on each volume element, as follows,
Once we loop over all elements and calculate error, we aggregate all element contributions in sumErrorFlux and sumErrorDiv and sumErrorJump which are \(\eta^2_{T,R,1}\), \(\eta^2_{T,R,2}\) and \(\eta^2_{e,R}\), respectively.
At this point, we will describe how to integrate over skeleton to get jumps on the faces. That involves loop over triangles and then for each triangle visiting adjacent tetrahedral, one by one.
On each triangle, we set some integration rule, which integration points are projected on appropriate sides of two adjacent tetrahedra. Next, for each tetrahedron, base functions (and derivatives) are evaluated at integration points and values of function \(u\) calculated. Once values on each tetrahedron are computed we do loop over all integration points on face and calculate norm of the jump, i.e. \(\eta_{e,R}\).
MoFEM has some dedicated data structures and methods to do this type of integration. Those procedures were implemented to give user ability to implement Discontinuous (Petrov) Galerkin, contact mechanics or other approaches involving integration on skeleton where information from adjacent entities is needed.
User entity operator MixTransport::MixTransportElement::OpSkeleton has nested volume element and nested entity operator to integrate over it. Note that nested volume element is a class MoFEM::VolumeElementForcesAndSourcesCoreOnSide, that is inherited from MoFEM::VolumeElementForcesAndSourcesCore. This derived class has additional functionality, which if an instance of it is called from face operator, it projects face integration points on the appropriate face of adjacent tetrahedra. As results volume, base functions are evaluated at integration points which come from currently evaluated skeleton face.
That nested volume element, here having instance volSideFe, run nested operator class MixTransport::MixTransportElement::OpSkeleton::OpVolSide, this class is derived form MoFEM::VolumeElementForcesAndSourcesCoreOnSide::UserDataOperator. Again this class gives access to additional information which is useful when integration is over skeleton, like face normal vector, face area, etc. Note that nested operator MixTransport::MixTransportElement::OpSkeleton::OpVolSide is added to nested volume instance volSideFe, in constructor of face operator with the command line
The example of implementation of nested volume element operator looks as follows
Implementation of doWork function is straightforward. It loops over integration points and computes function values using base functions and DOF values. Results are stored in the map valMap. Note that internal face has two adjacent volume elements, whereas face on boundary has only one. Each face has a unique orientation (sense) in respect to face, information about that sense is accessed by getSkeletonSense().
Once we evaluated approximation function values at each face, we can calculate error \(\eta_{e,R}\), using face operator
Note that we have to consider three scenarios, first, on the face is essential boundary condition. In that case, jump on face values is zero. If that is not a case, we run loop over adjacent volume elements
At this point nested volume element instance is called and then operator on this element executed. Results of this operation are stored in valMap.
If it is not case one, and if a face has only one volume in the side, thus on that face natural boundary is applied, then jump is a difference between boundary value and values evaluated by adjacent volume operator. If a face is in volume, i.e. third case, we calculate the difference between values from adjacent volumes. Results are stored on face tag values, here we are using MOAB to do that for us, using
which returns pointer to value stored (tagged) on face. Look here http://ftp.mcs.anl.gov/pub/fathom/moab-docs/contents.html#twofour to learn about tags in MOAB and how to use them.
Once we have implemented how to calculate jumps between adjacent volume elements, we can focus on computing residual error estimator. We do that in standard way using operator which acts on volume element
The scheme in which how we implement is similar to those above, we integrate values, save them on volume tags, and aggregate errors from individual elements. Note that we read tag values of previously calculated error from adjacent to tetrahedra faces, summing them up to calculate \( \sum_{e \in \partial T} \eta_{e,R}^2 \).
We will build a refined mesh from scratch, each time we add the new level. Using bit refinement levels (see Explaining mesh BitRefLevel) we can do that efficiently.
Since we build mesh without hanging nodes, not all edges in coarse tetrahedra are always refined. Refining such tetrahedra in subsequent refinements would result in poorly shaped elements. We will show how to overcome this difficulty.
Implementation of mesh refinement is in ExampleMix::refineMesh. First, we have to create a set of edges which are going to be split. This set is built from edges which were refined in previous mesh refinement levels and new edges which are adjacent to tetrahedra which have error above threshold. We used the standard "greedy" strategy for h-adaptive refinements, i.e. all elements which contribute 25% of the maximum element contribution to the square of total error in energy norm are marked for the refinement.
To get edges which have been refined in previous steps we run
To get entities which are deemed to refine at this level, we first get all elements which have error of 25% of the maximum element contribution
where ufe.errorMap is filled in MixTransport::MixTransportElement::OpError .
Once we have elements, we can find adjacent edges
and merge edges into the set of all edges which are refined or going to be refined
At that point we have elements and edges to refine so we can do mesh refinement. Mesh refinement is managed by interface MoFEM::MeshRefinement, we can query for that interface as follows
with this interface at hand, we do
If you like to contribute to this module (or MoFEM library), you are very welcome. Please feel free to add changes, including improving this documentation. If you like to work and modify this user module, you can fork this repository, make your changes, and do pull request. Contact us mofem-group@googlegroups.com or https://mofem.slack.com/ if you need any help or comments.
This is work in progress, and more stuff can be done. You could consider own paper or student project.
